


周圍的車輛和行人在接下來數(shù)秒中會做什么?要實(shí)現(xiàn)安全的自動駕駛,這是一個必須回答的關(guān)鍵問題,這也就是自動駕駛領(lǐng)域中的行為預(yù)測問題。
行為預(yù)測的難點(diǎn)在于周圍行人、車輛的不確定性和各種規(guī)則之外的行為。這些狀況難以用規(guī)則進(jìn)行總結(jié),因此最近研發(fā)人員們開始利用基于數(shù)據(jù)驅(qū)動的深度學(xué)習(xí)的方法,以達(dá)到更加合理的預(yù)測效果。
在這方面,來自 Waymo 和谷歌的團(tuán)隊(duì)提出了一系列用于自動駕駛行為預(yù)測的模型,讓無人車?yán)斫獬橄蟮牡缆翻h(huán)境,并實(shí)現(xiàn)對車輛、行人的多可能性預(yù)測。
在今年 6 月的一篇 CVPR 論文中,這個團(tuán)隊(duì)首先提出了一個全新模型 VectorNet。
在該模型中,團(tuán)隊(duì)首次提出了一種抽象化認(rèn)識周圍環(huán)境信息的做法:用向量(vector)來簡化地表達(dá)地圖信息和移動物體,這一做法拋開了傳統(tǒng)的用圖片渲染的方式,達(dá)到了降低數(shù)據(jù)量、計(jì)算量的效果。Waymo 也在其博客文章中明確表示,該技術(shù)提高了其行為預(yù)測的精準(zhǔn)度。
近日,這個團(tuán)隊(duì)公布了進(jìn)一步的工作,提出了 TNT (Target-driveN Trajectory Predictio)。TNT 是一種目的地引導(dǎo)的軌跡預(yù)測方法,運(yùn)用了監(jiān)督學(xué)習(xí)的方法對車輛和行人進(jìn)行多軌跡回歸,最終的模型能夠輸出多個未來軌跡的預(yù)測,同時明確指出各個軌跡可能性。
論文中介紹,TNT 在公開數(shù)據(jù)集 Argoverse 的測試表現(xiàn)與冠軍結(jié)果相當(dāng),同時在 INTERACTION、Stanford Drone,以及 Waymo 內(nèi)部數(shù)據(jù)集中取得了非常好的效果。
目前該論文已經(jīng)被國際機(jī)器人(15.170, -0.10, -0.65%)學(xué)習(xí)會議 CoRL(Conference on Robot Learning)接收。

預(yù)測多種可能的未來情形
Waymo 在博客中指出,VectorNet 突破性地提出了用向量的方式來抽象化表達(dá)這個世界,從而感知、理解周圍環(huán)境。在理解環(huán)境以后,下一步就是實(shí)現(xiàn)更好的行為預(yù)測。
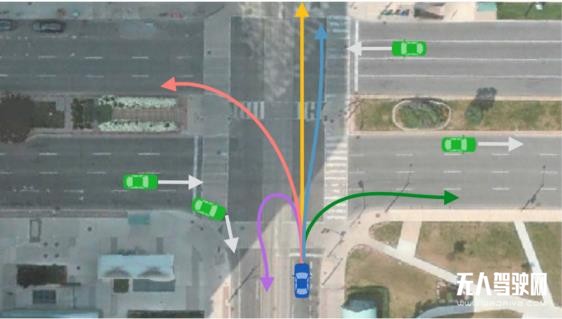
自動駕駛行為預(yù)測和其他問題不一樣的地方在于,周圍的車輛、行人在接下來數(shù)秒時間里有多種行進(jìn)的可能性。這些可能性本身也將影響自動駕駛車輛的決策規(guī)劃。
比方說,如果機(jī)器能算出:前方車輛有 80% 的概率左轉(zhuǎn)、20% 的概率右轉(zhuǎn),自動駕駛車輛都能根據(jù)這一結(jié)果進(jìn)行更好的決策規(guī)劃。同時對機(jī)器來說,就算別的車輛只有 1% 的可能性右轉(zhuǎn),這種可能性也不能被忽視。
而這種針對多種可能性的多軌跡預(yù)測,有著很大的技術(shù)難度。當(dāng)下的神經(jīng)網(wǎng)絡(luò)難以很好應(yīng)對多軌跡預(yù)測的任務(wù)。
據(jù)業(yè)內(nèi)人士介紹,神經(jīng)網(wǎng)絡(luò)擅長于一對一和多對一的擬合問題,而非一對多的問題。多對一如常見的分類問題,輸入多張車輛的照片,神經(jīng)網(wǎng)絡(luò)能準(zhǔn)確識別這些照片為 “車” 的類別。一對一如常見的回歸問題,輸入一張車輛的照片,神經(jīng)網(wǎng)絡(luò)能估計(jì)它的長寬高等尺寸。但如果輸入一個樣本,想讓神經(jīng)網(wǎng)絡(luò)回歸出三個結(jié)果,這是神經(jīng)網(wǎng)絡(luò)所不擅長的事情。
據(jù)介紹,現(xiàn)在市面上基礎(chǔ)的方案是基于交通規(guī)則獲得周圍車輛、行人的行進(jìn)可能性。如果交規(guī)允許這條道路直行、左右轉(zhuǎn),那么就算三種可能性。但這種方式的預(yù)測結(jié)果并不完全可靠,因?yàn)橐?guī)則之外的案例并未被考慮其中,如借道,違法掉頭,事實(shí)上,要保障自動駕駛長時間運(yùn)行下的安全性,應(yīng)對規(guī)則之外的情形的能力非常重要。
近兩年的論文內(nèi)容顯示,很多團(tuán)隊(duì)正在嘗試使用生成模型來進(jìn)行多軌跡預(yù)測。即利用如 GAN,VAE 等模型在隱空間 latent space 進(jìn)行采樣,得到周圍目標(biāo)在特定場景下的多種潛在選擇。
但依靠生成模型的問題在于,樣本采集存在很大的隨機(jī)性,這對一個要求可靠的系統(tǒng)來說是難以接受的。假設(shè)前方來車左拐的可能性有 90%,右拐的可能性有 10%,用采樣的方法很有可能我們采樣三次得到的都是左拐,而忽略了它往右拐的可能性。在自動駕駛領(lǐng)域,依靠這種方式的行為預(yù)測難以進(jìn)行實(shí)際應(yīng)用。
用監(jiān)督學(xué)習(xí)實(shí)現(xiàn)精準(zhǔn)預(yù)測
該團(tuán)隊(duì)提出的 TNT 首次運(yùn)用了監(jiān)督學(xué)習(xí)的方法對車輛和行人進(jìn)行多軌跡預(yù)測,是一種目的地引導(dǎo)的軌跡預(yù)測方法。其模型的最大貢獻(xiàn),就是能夠不依靠采樣,純靠監(jiān)督學(xué)習(xí)來進(jìn)行多軌跡的行為預(yù)測。
具體來說,該模型的行為預(yù)測按順序分為三步,每一步都有著特定目標(biāo):1、利用地圖的先驗(yàn)信息,離散化并預(yù)測目的地;2、在預(yù)測目的地基礎(chǔ)之上,進(jìn)一步預(yù)測目標(biāo)的運(yùn)行軌跡;3、在預(yù)測出多條運(yùn)行軌跡當(dāng)中,對每條軌跡進(jìn)行篩選和打分,預(yù)測出各個選擇的可能性,也同時選擇出可能性最高的幾個運(yùn)行軌跡。
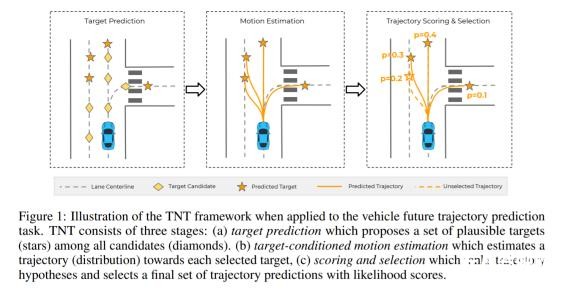
在技術(shù)層面,運(yùn)用監(jiān)督學(xué)習(xí)的好處在于能夠讓最終的模型給出多個未來軌跡的預(yù)測,同時明確指出各個軌跡可能性。比如在輸出三個軌跡的情況下,模型能夠明確指出,30% 可能性左轉(zhuǎn)、30% 可能性右轉(zhuǎn),直行的可能性為 40%。這樣的預(yù)測結(jié)果就能真正地被決策系統(tǒng)所使用。
在最終的表現(xiàn)上,單個 TNT 模型的行為預(yù)測準(zhǔn)確性在公開數(shù)據(jù)集 Argoverse 的測試表現(xiàn)與冠軍結(jié)果相當(dāng),同時在 INTERACTION、Stanford Drone 等測試中取得了非常好的效果。






















